引言
Labeled LDA (L-LDA)是一个有监督的机器学习模型,主要应用是多类标分类,即给一篇文档打上多个类标。与LDA最大的不同之处为:L-LDA的主题限定为文档的类标集合,也就是说生成过程中的主题就是这些类标,不用人工指定主题数。
模型理解
L-LDA模型与原始LDA模型基本相同,变化很小,下面的理解全部参考原始论文[1]。
L-LDA概率图模型如下:
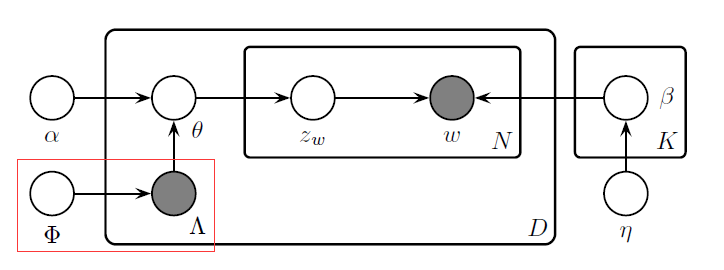
去掉左下角Phi和Lamda所指向两条边就是原始的LDA主题模型。
其中:
- N(d) 是文档d的词数目
- K是主题数目,也是类标数目,在L-LDA中,主题和类标是等价的
- Alpha是主题共轭先验分布的参数,K维,Dirichlet分布(预先指定)
- Eta是词共轭先验分布的参数,K维,Dirichlet分布(预先指定)
- Eta(k)是主题k的词分布(多项分布)
- Theta(d)是文档d的主题分布(多项分布)
- Phi是主题先验分布,或者说类标先验分布,K维(预先统计)
- Lambda(d)为K维指示向量,每一维度取值0或者1,表示文档d是否属于这个主题
生成过程如下:

说明:
- 步骤1和2生成每个主题下的词分布,和原始LDA一样
-
步骤4-5统计文档d的K维指示向量,1表示文档d属于这个主题,0表示不属于,进而可以得到文档d的类标投射矩阵L(d),通过伯努利实验生成。假设有4个主题,文档d属于主题2和主题3, 那么L(d)表示为2*4的矩阵(第一行仅第2列为1, 第二行仅第3列为1):
0 1 0 0 0 0 1 0
-
步骤6根据类标投射矩阵L(d)得到文档d的超参数向量alpha(d),原始alpha是K维,投影后变为M(d)维,其实就是文档d的类标数。还是使用上面的例子,文档的d包含主题2和3,那么这里M(d)就等于2,Alpha(d) = L(d)*Alpha = {alpha2, alpha3}
- 步骤7根据alpha(d)生成M(d)个主题的分布theta(d),与原始LDA不同,此处将主题限定在文档d对应的M(d)个主题中
- 步骤8-10 同原始LDA一样,先生成主题,再根据主题生成词
注:步骤4-6可能是论文为了形式化,写的有点复杂,实际实现的时候没有这个伯努利实验的过程,直接从训练数据得到文档的类标,训练的时候主题限定在这个类标集合内进行Gibbs采样。
算法实现
搜索了一下,有如下的开源实现:
- http://www-nlp.stanford.edu/software/tmt/tmt-0.4/ (scala)
- https://github.com/myleott/JGibbLabeledLD (java)
- https://github.com/shuyo/iir/blob/master/lda/llda.py (python)
但是没有看到C++的,其实可以基于 GibbsLDA++ 来改,只需要很小的改动就可以实现,这里说下大体思路,等有时间再实现:
- 文档结构体中保留每篇文档的类标
- Gibbs采样的时候,只在当前文档对应的类标集合里面采样,如果文档都是单类标,那么就不用采样。
- 预测函数不用变化,在新文档上得到所有主题的概率。如果是单类标分类,那么输出概率最大的主题;如果是多类标分类,输出大于一定阈值的所有主题。
相关参考
- [1] Labeled LDA: A supervised topic model for credit attribution in multi-labeled corpora (pdf)