sklearn全称为scikit-learn,是目前很流行的一个基于python的机器学习包,基本覆盖了常见的机器学习算法,如分类、回归、聚类、特征选择、模型选择以及数据预处理等任务对应的算法。文档和示例非常丰富,可视化展示也很方便,所以使用者众多,尤其是在 Kaggle 数据分析竞赛中被参赛者广泛使用。
关于该工具包的使用介绍网上已经非常多,所以这里只是整理和记录自己使用的一些心得。
初始入门
最好入门方法就是参考官网的 Tutorials
sklearn集成了一些常用的数据集,以方便测试相关算法,封装为datasets模块,如导入分类数据集合iris和digits,导入回归数据集diabetes
from sklearn import datasets
iris = datasets.load_iris()
digits = datasets.load_digits()
diabetes = datasets.load_diabetes()
具体如何在这些数据集合应用相关算法,官网Tutorials有详细的介绍,下面重点讲下文本分类。
文本分类
1. 加载数据
数据集选取的是20newsgroups,该数据集包含20个新闻组约2万篇文档,加载方式也是通过sklearn.datasets模块,但是稍有不同,如下
from sklearn.datasets import fetch_20newsgroups
twenty_train = fetch_20newsgroups(subset='train', shuffle=True, random_state=42)
从上面可以看出,加载数据集实际上是调用函数fetch_20newsgroups()
在python命令行输入help(fetch_20newsgroups),可以查看相应参数说明,其中
- subset: 指定加载训练集或测试集,或者两者,取值对应’train’, ‘test’, ‘all’
- data_home: 指定20newsgroups数据集所在路径,默认为 ‘~/scikit_learn_data’,Windows下对应为C:\Users\xxx\scikit_learn_data
- categories: 指定要加载的类别list,默认为None,表示所有类别
- shuffle: 是否要混洗数据
- random_state: 混洗随机数的种子值
- download_if_missing: 指定data_home下不存在数据集时是否下载,默认为True,表示下载
- remove: 指定预处理文本的过滤策略,取值为元组 (‘headers’, ‘footers’, ‘quotes’)
刚开始测试这个数据集的时候,老是等半天没有结果。于是看了下对应的源代码./site-packages/sklearn/datasets/twenty_newsgroups.py,发现第一次加载的时候会下载数据集到~/scikit_learn_data/20news_home,下载完成后会解压然后压缩生成cache文件,即~/scikit_learn_data/20news-bydate.pkz,以后每次加载就读取该文件了。
所以首次加载的时候需要有点耐心,大概等待7分钟左右吧(国内环境)。
当然也可以自己下载放到目录~/scikit_learn_data/20news_home,下载地址为:http://people.csail.mit.edu/jrennie/20Newsgroups/20news-bydate.tar.gz (文件大小为13.7M)
2. 特征选择
最常见的就是词袋模型,每个词就是一个特征,特征权重为词频,通过构建CountVectorizer 来向量化每篇文档:
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer(min_df=1)
corpus = [
'This is the first document.',
'This is the second second document.',
'And the third one.',
'Is this the first document?',
]
X = vectorizer.fit_transform(corpus)
print vectorizer.get_feature_names()
#[u'and', u'document', u'first', u'is', \
#u'one', u'second', u'the', u'third', u'this']
for word,index in sorted(vectorizer.vocabulary_.items(), key = lambda x: x[1]):
print "%s\t%d" % (word, index)
# and 0
# document 1
# first 2
# is 3
# one 4
# second 5
# the 6
# third 7
# this 8
for v in X:
print v.toarray()
# [[0 1 1 1 0 0 1 0 1]]
# [[0 1 0 1 0 2 1 0 1]]
# [[1 0 0 0 1 0 1 1 0]]
# [[0 1 1 1 0 0 1 0 1]]
print vectorizer.transform(['Something completely new.']).toarray()
# [[0 0 0 0 0 0 0 0 0]]
上面代码中:
- 函数fit_transform()会在训练数据上训练一个Vectorizer,并将训练数据向量化,由于文本特征维度较高,这里是用稀疏矩阵保存
- 函数get_feature_names()得到特征名称的list, 特征名称为unicode字符串,而vectorizer的成员变量vocabulary_恰好是特征名称到特征索引的dict,这个索引就是get_feature_names()得到特征list的下标
- 函数transform()将新的文本向量化
通常情况下,每个特征权重会取tf-idf值,这个时候就应该使用 TfidfVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(min_df=1, use_idf=True)
X = vectorizer.fit_transform(corpus)
features = vectorizer.get_feature_names()
for i,idf in enumerate(vectorizer.idf_):
print "%s\t%.5f" % (features[i].encode('utf-8'), idf)
# and 1.91629
# document 1.22314
# first 1.51083
# is 1.22314
# one 1.91629
# second 1.91629
# the 1.00000
# third 1.91629
# this 1.22314
TfidfVectorizer成员函数与CountVectorizer一样,但是多了成员变量idf_, 为每个特征idf值构成的list。如果仅仅需要统计一份idf词表出来,也可以用TfidfVectorizer,idf计算公式为log((N+1)/(df+1))+1,分子分母都+1是假定增加一篇文档包含所有词。
其他说明
- 如果有自己的词表,相当于预先指定了特征,那么可以用 DictVectorizer
- 如果需要考虑短语或多词表达式,或者说考虑词之间的次序依赖关系,那么可以引入ngram模型,当ngram特征非常大的时候,需要考虑使用 HashingVectorizer
3. 分类实验
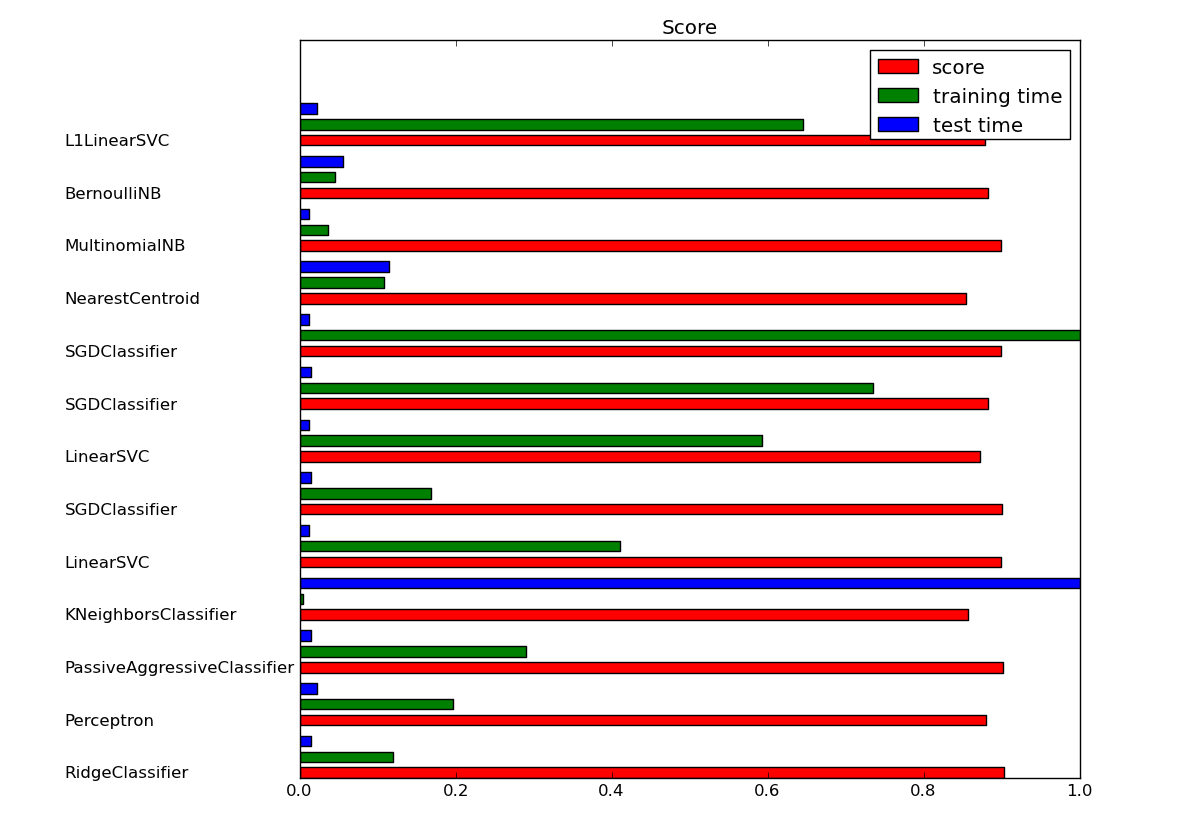
直接参考文章: Classification of text documents using sparse features
演示常见分类算法的效果,并且还使用卡方测试选取有效文本特征进行降维后再进行分类,运行结果如下: